Failover & Recovery with Repmgr in PostgreSQL 11

Configuring replication for databases is the best strategy towards achieving high availability. PostgreSQL streaming replication using Repmgr can satisfy this requirement and PostgreSQL being our key database in Smallcase analytics, it’s important to keep it highly available and be failover resistant. In this blog, we will see how to do this using REPMGR and fully automate recovery and failover. We have also made use of Postgres triggers to bring back our cluster when the failed node comes up.Underlying configurations are done for UBUNTU 18.04, you can go ahead and explore the methodology and replicate for others as well.
How Does Replication Work in PostgreSQL
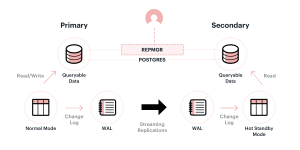
In a PostgreSQL replication setup, you have 2 types of servers. A master server and a slave server. The database records of the master server get replicated in real-time to the Slave servers. You can read from the slave servers using the IP addresses of the slave servers. But you can add new data only to the master server. So if any of the master servers fails, one of the slave servers can take over and become the new master. That’s how PostgreSQL can handle database requests without any interruption even if some of the servers fail in a master/slave configuration.
Postgres and Repmgr Installation and Configuration
Both the nodes should have this configuration
>>apt-get install apt-transport-https
>>echo "deb https://dl.2ndquadrant.com/default/release/apt stretch-$2ndquadrant main" > /etc/apt/sources.list.d/2ndquadrant.list
>>wget --quiet -O - https://dl.2ndquadrant.com/gpg-key.asc | apt-key add -
>>apt-get install postgresql-11 postgresql-11-repmgr
>>systemctl stop postgresql
>>echo "postgres ALL = NOPASSWD: /usr/bin/pg_ctlcluster" > /etc/sudoers.d/postgres
It’s important that the nodes can inter-SSH via Postgres user (Why? We will come to that later, so, for now, paste the public key in the data directory and the private key in .ssh sub-folder).
Once the installation is complete, we will change the Postgres and Repmgr config so that they can communicate with each other.
In postgresql.conf(default: /etc/postgresql/11/main/) change the following entries.
listen_addresses = '<subnet CIDR Block>'(So that it can listen from all nodes in same network, or keep it '*' to listen from anywhere)
shared_preload_libraries = 'repmgr'
max_wal_senders = 15
max_replication_slots = 15
wal_level = 'replica'
hot_standby = on
archive_mode = on
archive_command = ''(a cp command to any directory you want archives to be saved)
In pg_hba.conf ( default: /etc/postgresql/11/main/) add the following configurations.
host repmgr repmgr PRIMARY IP/32 trust
host repmgr repmgr SECONDARY IP/32 trust
host replication repmgr PRIMARY IP/32 trust
host replication repmgr SECONDARY IP/32 trust
Run **sudo systemctl restart postgresql** to reflect the changes made above. Your Postgres should be listening on port 5432 if all configurations are correct till now. If not stop here and check the configurations again.
Configuring the Primary server
In Postgres data directory (Default:/var/lib/Postgresql) create a Repmgr superuser and a Repmgr database where it will save the state of all nodes and events happening in the cluster
createuser --replication --createdb --createrole --superuser repmgr
createdb repmgr -O repmgr
Next, we will make changes to repmgr.conf to register the current node as primary
cluster=cluster
node_id=1
data_directory='/var/lib/postgresql/11/main'
node_name=node1
conninfo='host=ip user=repmgr dbname=repmgr'
failover=automatic
promote_command='repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='repmgr standby follow -f /etc/repmgr.conf --log-to-file'
log_file='/var/log/postgresql/repmgr.log'
log_level=NOTICE
reconnect_attempts=4
reconnect_interval=5
In this file, only 4 parameters are mandatory: node_id, node_name, conninfo, data_directory. You can find a documented Repmgr.conf [HERE].Now it’s easier to keep a check on Repmgr if you run it as a daemon (at /etc/default/Repmgrd)
REPMGRD_ENABLED=yes
REPMGRD_CONF="/etc/repmgr.conf"
Restart your Repmgrd service for it to reload as a daemon.
>>sudo service repmgrd restart
**Note** You can check if repmgrd is running with “ps aux | grep repmgrd“. If not the case, then run repmgrd manually to check for errors.There is also an issue with repmgrd which does not load the right path for the pg_ctl Postgresql. To solve it just create a symbolic link.
>>sudo ln -s /usr/lib/postgresql/11/bin/pg_ctl /usr/bin/pg_ctl
To register your primary node
>>repmgr primary register >>repmgr cluster show
Great, you have added your primary node!
Configuring the Secondary server
cluster=cluster
node_id=2
data_directory='/var/lib/postgresql/11/main'
node_name=node2
conninfo='host=ip user=repmgr dbname=repmgr'
failover=automatic
promote_command='repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='repmgr standby follow -f /etc/repmgr.conf --log-to-file'
log_file='/var/log/postgresql/repmgr.log'
log_level=NOTICE
reconnect_attempts=4
reconnect_interval=5
Similar to primary node at /etc/default/repmgrd
REPMGRD_ENABLED=yes
REPMGRD_CONF="/etc/repmgr.conf"
Restart your repmgrd service for it to reload as daemon.
sudo service repmgrd restart
Register your secondary node
>>sudo systemctl stop postgresql
>>repmgr -h masterIP -U repmgr -d repmgr standby clone
>>sudo systemctl start postgresql
>>repmgr cluster show
You have your cluster setup.

Test Failover with Repmgr
To simulate a failover of primary stop Postgres in primary and simultaneously watch the repmgr logs (`tail -f /var/log/postgresql/repmgr/log`) in the standby node.And now if you see the standy –> primary happened very quickly but what happens once your old primary comes up, repmgr somehow is not able to automatically update that node and bring it up as standby until you manually register it as SECONDARY and you will come across a situation where repmgr has two primary nodes running( one active and one inactive)

This is how your node status will look like.The workaround for this is a postgresql functionality of triggers. By now, you must have figured that repmgr maintains a database of it’s own where it has certain tables, one of them is ‘events’.
>>psql -U repmgr
>>dt
>>select * from table events;
Now the idea is to put an update trigger on table events so that when an event **'standby_promote'**
is added to the table, a script is triggered that will bring back the old primary as the new standby
Automated Recovery with Repmgr
The script I invoked was a bash script, therefore I needed *.plsh* extension in my database. You can write it in any other language and install the required extension
>>cd /usr/share/postgresql/11/extension/ >>sudo git clone https://github.com/petere/plsh.git >>cd plsh >>sudo make PG_CONFIG=/usr/bin/pg_config >>sudo apt-get install make >>sudo apt-get install gcc >>sudo apt-get install postgresql-server-dev-11 >>sudo make install PG_CONFIG=/usr/bin/pg_config Once it's installed, login to Repmgr database and create the extension. >>Psql -U repmgr >>Create extension plsh; (Execute this only on the primary node.) Next, we will create a function and a trigger to invoke the script.
>>sudo -i -u postgres >>psql Create a function that executes the failover_promote script when invoked. >>CREATE FUNCTION failover_promote() RETURNS trigger AS $$ #!/bin/sh /bin/bash /var/lib/postgresql/failover_promote.sh $1 $2 $$ LANGUAGE plsh; Create an update trigger on events table to inoke the function we created above. >>create trigger failover after insert on events for each row execute procedure failover_promote(); You can create a failover_promote.sh in `/var/lib/postgresql` or any other location but it should be similar to the location mentioned in the function. You can clone failover_promote.sh that I used from [here]. You can change the script according to your use case but the idea is for an action plan once primary fails.
Test fully automated failover with Repmgr
To simulate a failover of primary stop Postgres in primary and simultaneously watch the repmgr logs (`tail -f /var/log/postgresql/repmgr/log`) in standby node.
In the logs, the standby is promoted to the new primary and after that, it’s trying to ping the failed node and the moment it’s reachable will back up the latest data on the old primary and bring it up as new standby.
Yes, finally it’s done.
I know configuring this is a task and there may be areas where you might differ with me. Please feel free to comment if you have any questions.

You may want to read
 Open Sourcing URL Shortener
Open Sourcing URL Shortener
 Scaling smallcase offers using Kafka
Scaling smallcase offers using Kafka
 Micro-frontend in smallcase
Micro-frontend in smallcase