Automation using Bull Queues to face bear market

The Problem
At smallcase, there are numerous tasks (or jobs) that need to run through the day. Some of these jobs are periodic – happening every hour or every day, some jobs are ad-hoc, and some jobs are one-time fixes.
These jobs achieve various goals for the platform. For example, a job can be responsible for fetching the stock prices from upstream that are shown on the platform. It could also be generating various ledgers, or scraping sites for information, or fetching relevant news articles to display for smallcases. Some jobs are for internal utility as well, for instance, backing-up data from the database at the end of the day, getting health report from various services.
Current Solution
As you can see, there could be hundreds of jobs that need to be run frequently and periodically. For this, we have developed a service for scheduling jobs that run on a predefined configuration. The smallcase scheduler is powered by Bull (a Redis-based queue for handling jobs) and a customized fork of Arena which serves as a UI dashboard for the scheduler.
Architecture
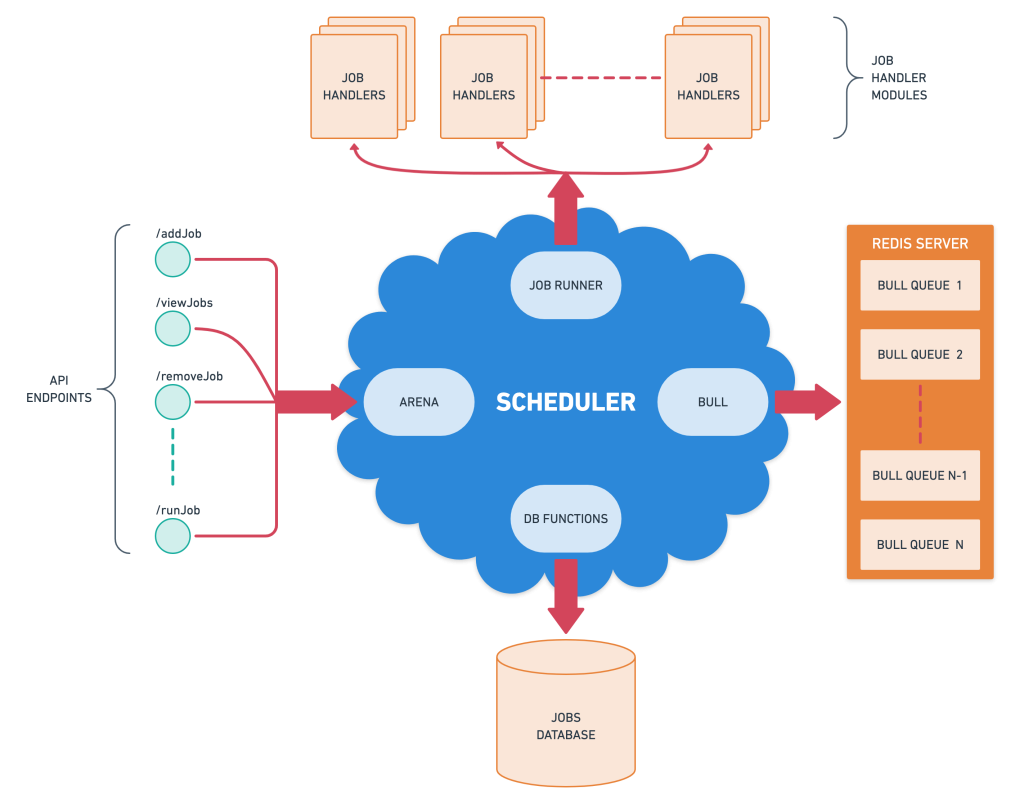
The Bull is in control of creating and maintaining the state of the queues for jobs. These queues are cheap and each queue provides configurability option for its concurrency. After initialization of the queues, the scheduler service is responsible for fetching the job configurations from the Jobs Database and initializing the jobs inside the respective queues. If the job has a cron-time identifier, Bull handles the timing specifics for the Job.
The Arena dashboard provides details about the queues and information about the jobs that have run and are going to run. It also gives the ability to add jobs, remove jobs or run jobs.
If a job has to be executed it goes through the job-runner module which decides how the job should be run. As mentioned earlier, the jobs are of different types and functional separation of jobs can exist by segregating the jobs into different independent modules. For example, in-house utility jobs like a backup of the database can reside inside a particular job-handler module while a job like scraping can reside in another job-handler module.
Design
Bull Queues
Bull has many advantages over other job queue solutions (like Keu and Bee). Some highlights of the advantages that it provides are – supports repeatable jobs, rate limiters, sandboxed workers etc. By leveraging the polling-free design of Bull, the scheduler can support scheduling of periodic jobs very easily and without being an overhead for the CPU.
Job Specification
The job specification in the database needs to provide details about the job. The configuration of the job can include fields like cron-time, job-handler, additional options (like arguments if the job is a CLI command), kill interval (time after which the scheduler will kill the job) etc. With these configurations specified in the config, the scheduler is able to trigger the job at the given time.
Job Runner
To run jobs the job-runner spawns a separate process to run the job. This helps in sandboxing so that if the job crashes it does not affect the scheduler. It also has its use that if the job is CPU intensive, it will not block the scheduler and jobs will not stall. The job-runner also needs to be aware of the dependencies of the job if it is specified in the job configuration. For example, a job J1 can have its dependency as another job J2 specified in the config. If so, the job-runner needs to delay J1 until J2 has finished.
Arena
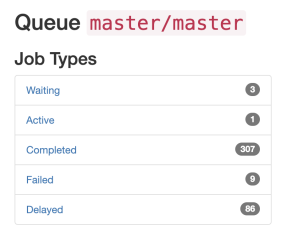
A Bull Queue showing status of jobs
With modifications to the Arena, it can be used as a dashboard to play with jobs of the scheduler. It also gives rich flexibility for use because Arena is also aware of Bull queues, therefore modifications to jobs like updating job in the queue, or removing a job from the queue or adding a new job are straightforward. It also provides statistics and reports giving detailed insight into the jobs that were executed.
Summary
Scheduling numerous scripts and jobs on a periodic basis while providing configurable options for each one requires a proper automation and monitoring service. The smallcase scheduler presents such a solution by intelligently providing configuration options for each job, managing the job lifecycle, and giving easy access to the features through a single dashboard.
Have you done a similar kind of automation for scheduling jobs? What were the challenges and how did you go about it? Let me know in the comments 🙂

You may want to read
 Polling reliably at scale using DLQs
Polling reliably at scale using DLQs
 Field-level encryption in MongoDB community server, using Node JS and Mongoose
Field-level encryption in MongoDB community server, using Node JS and Mongoose
 Scaling smallcase managers’ microsite with Next.js
Scaling smallcase managers’ microsite with Next.js